We built memory for individuals and achieved SOTA on LoCoMo benchmark


CORE became SOTA on the LoCoMo benchmark with overall 88.24% accuracy.
LoCoMo tests how well AI systems remember and reason across long conversations (300+ turns). Think of it as the SAT for AI memory - it evaluates whether systems can maintain context, resolve contradictions, and surface relevant information as conversations evolve over time.
That 88.24% isn't just a score. It's proof that we have built a memory that can finally work the way the human mind does.
Benchmark Setup
- Dataset: LOCOMO benchmark - 1,540 questions across 10 multi-turn conversations
- Model: GPT 4.1
- Metrics: Testing accuracy on single hop recall, multi-hop reasoning, open domain synthesis, and temporal understanding
- Repo: Complete reproducible benchmark in our github
Results
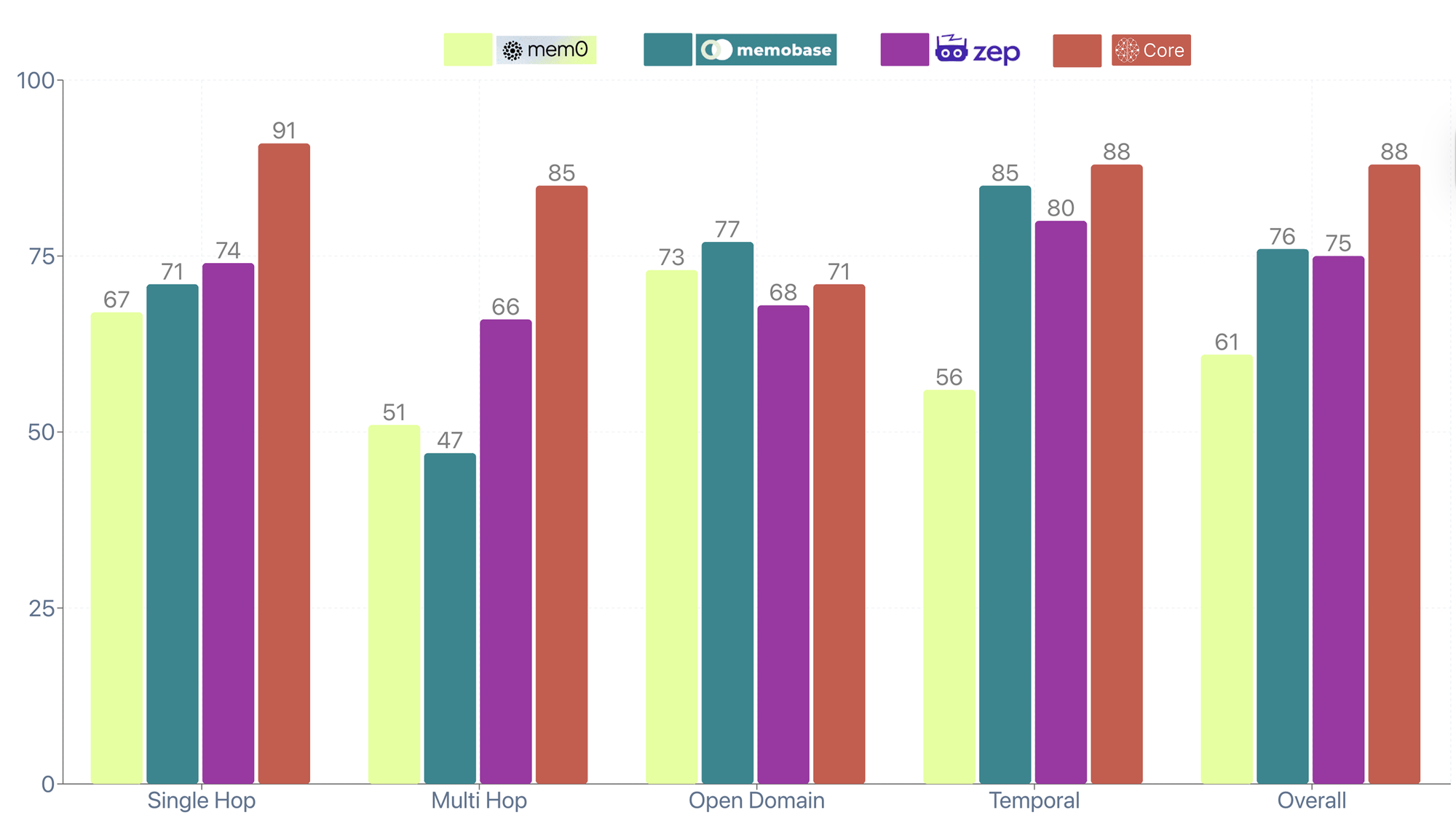
- Single-hop: 91% (simple recall - "What's your favourite framework?")
- Multi-hop: 85% (connecting facts - "Who else uses React on your team?")
- Temporal: 88% (tracking changes - "When did you switch to Next.js?")
- Open Domain: 71% (world knowledge )
- Overall: 88%
Key Insights
- Core dominates across all categories - especially temporal reasoning (88%) where individual memory complexity matters most.
- Temporal performance is the key differentiator. Core handles the contradictions and evolution that define individual memory.
The Problem: Memory for Individuals
You brainstorm in ChatGPT, debug in Cursor, try a new coding agent and re-explain everything from scratch. With every new AI tool, the cost of context switching grows.
Why Memory isn't just a simple database
Human memory is messy: contradictory, evolving, story-driven. You loved React but maintain legacy code. You moved cities yet still work remotely. You learn Rust for fun but rely on Python at work. A static database or .md file can’t reconcile this.
What real memory must capture
- Context matters → “Use Kubernetes?” depends on team size, skills, history.
- Evolution matters → A migration isn’t just a timestamp but the reasoning behind it.
- You own it → Memory should travel with you across jobs, teams, and tools.
- Built for how humans think → We think in narratives, contradictions, and context, not neat rows in a table.
Building memory system for an individual is harder because it needs to mirrors how humans think. The challenge isn’t storing facts - it’s preserving context, evolution, and ownership in a way that agents can actually use.
Solution: How CORE works
How CORE creates memory
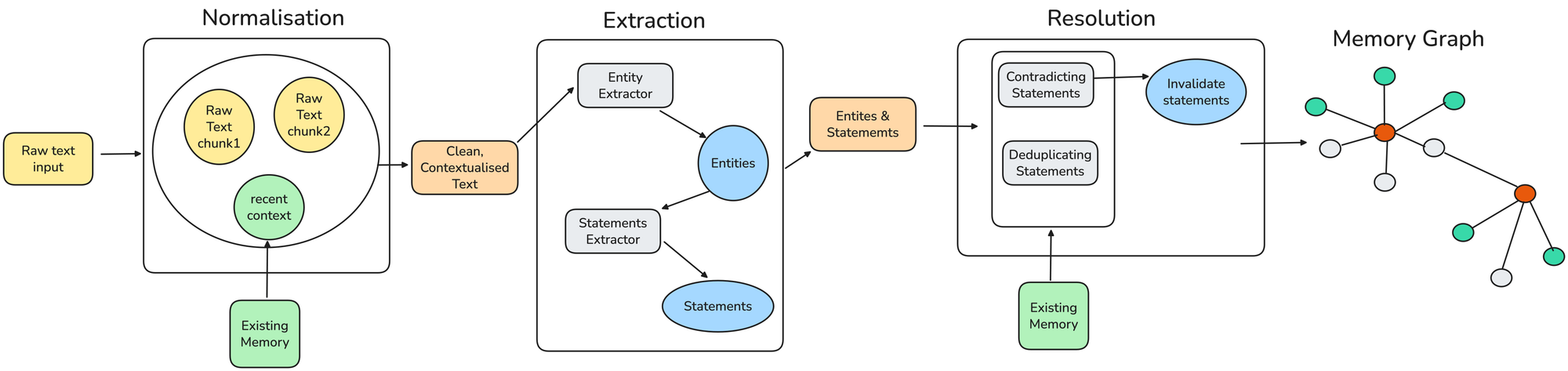
CORE’s ingestion pipeline has four phases designed to capture evolving context:
- Normalization: Links new information to recent context, breaks long documents into coherent chunks while keeping cross-references, and standardizes terms so by the time CORE extracts knowledge, it’s working with clean, contextualized input instead of messy text.
- Extraction: Pulls meaning from normalized text by identifying entities (people, tools, projects, concepts), turning them into statements with context, source, and time, and mapping relationships. For example, “We wrote CORE in Next.js” becomes: Entities (Core, Next.js), Statement (CORE was developed using Next.js), and Relationship (was developed using).
- Resolution: Detects contradictions, tracks how preferences evolve, and preserves multiple perspectives with provenance instead of overwriting them so memory reflects your full journey, not just the latest snapshot.
- Graph Integration: Connects entities, statements, and episodes into a temporal knowledge graph that links facts to their context and history, turning isolated data into a living web of knowledge agents can actually use.
The Result: Instead of a flat database, CORE gives you a memory that grows and changes with you - preserving context, evolution, and ownership so agents can actually use it.
How CORE recalls from memory
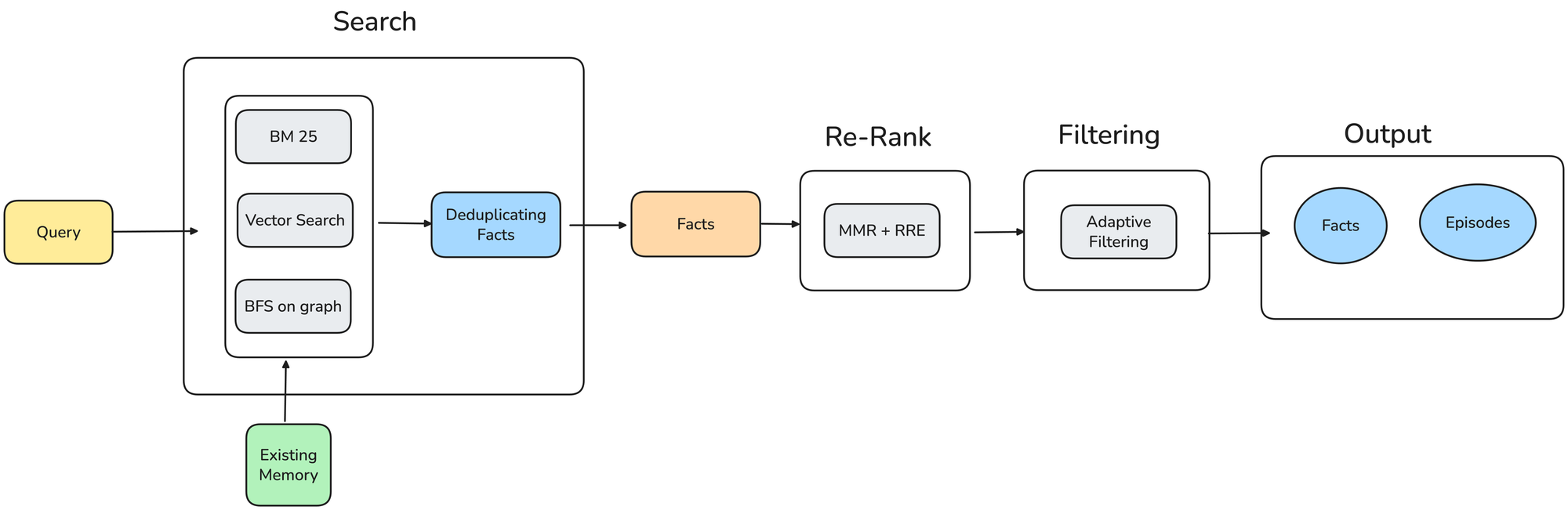
When you ask CORE a question, it doesn’t just look up text - it digs into your whole knowledge graph to find the most useful answers.
- Search: CORE looks through memory from multiple angles at once - keyword search for exact matches, semantic search for related ideas even if phrased differently, and graph traversal to follow links between connected concepts.
- Re-Rank: The retrieved results are reordered to highlight the most relevant and diverse ones, ensuring you don’t just see obvious matches but also deeper connections.
- Filtering: CORE applies smart filters based on time, reliability, and relationship strength, so only the most meaningful knowledge surfaces.
- Output: You get back both facts (clear statements) and episodes (the original context they came from), so recall is always grounded in context, time, and story.
The result: CORE doesn’t just recall facts - it recalls them in the right context, time, and story, so agents can respond the way you would remember.
Conclusion
By achieving 88.24% accuracy on LoCoMo, CORE takes the first step toward a digital brain that mirrors human memory, with all its contradictions, evolution, and narrative complexity.
With memory, every AI agent you use can access your history, preferences, decisions, and past context, making AI more like a thinking partner than generic assistant.
As we move toward AGI, systems that remember us best will deliver the most meaningful experiences, and CORE is building that memory layer today.
CORE is open-source
We’re building CORE in public—and it’s fully open source. If you share our vision of memory that belongs to individuals, not platforms:
- ⭐ Star us on GitHub to support open source memory for individuals
- 🚀 Try CORE today:
- Quick start: Sign up at core.heysol.ai
- Self-host: Run locally with
docker compose up
Own your memory. Power your agents.

